


Новости

11.05.2020
Книга «Python: Искусственный интеллект, большие данные и облачные вычисления»
В вашем распоряжении более пятисот реальных задач — от фрагментов до 40 больших сценариев и примеров с полноценной реализацией. IPython с Jupyter Notebooks позволят быстро освоить современные идиомы программирования Python. Главы 1–5 и фрагменты глав 6–7 сделают понятными примеры решения задач искусственного интеллекта из глав 11–16. Вы познакомитесь с обработкой естественного языка, анализом эмоций в Twitter, когнитивными вычислениями IBM Watson, машинным обучением с учителем в задачах классификации и регрессии, машинным обучением без учителя в задачах кластеризации, распознавания образов с глубоким обучением и сверточными нейронными сетями, рекуррентными нейронными сетями, большими данными с Hadoop, Spark и NoSQL, IoT и многим другим. Вы поработаете (напрямую или косвенно) с облачными сервисами, включая Twitter, Google Translate, IBM Watson, Microsoft Azure, OpenMapQuest, PubNub и др.
9.12.2. Чтение CSV-файлов в коллекции DataFrame библиотеки pandas
В разделах «Введение в data science» предыдущих двух глав были представлены основы работы с pandas. Теперь продемонстрируем средства pandas для загрузки файлов в формате CSV, а затем выполним базовые операции анализа данных.
Наборы данных
В практических примерах data science будут использованы различные бесплатные и открытые наборы данных для демонстрации концепций машинного обучения и обработки естественного языка. В интернете доступно огромное количество разнообразных бесплатных наборов данных. Популярный репозиторий Rdatasets содержит ссылки на более чем 1100 бесплатных наборов данных в формате CSV. Эти наборы изначально поставлялись с языком программирования R, чтобы упростить изучение и разработку статистических программ, тем не менее, они не связаны с языком R. Сейчас эти наборы данных доступны на GitHub по адресу:
https://vincentarelbundock.github.io/Rdatasets/datasets.html
Этот репозиторий настолько популярен, что существует модуль pydataset, предназначенный специально для обращения к Rdatasets. За инструкциями по установке pydataset и обращению к наборам данных обращайтесь по адресу:
https://github.com/iamaziz/PyDataset
Другой большой источник наборов данных:
https://github.com/awesomedata/awesome-public-datasets
Одним из часто используемых наборов данных машинного обучения для начинающих является набор данных катастрофы «Титаника», в котором перечислены все пассажиры и указано, выжили ли они, когда «Титаник» столкнулся с айсбергом и затонул 14–15 апреля 1912 года. Мы воспользуемся этим набором, чтобы показать, как загрузить набор данных, просмотреть его данные и вывести характеристики описательной статистики. Другие популярные наборы данных будут исследованы в главах с примерами data science позднее в этой книге.
Работа с локальными CSV-файлами
Для загрузки набора данных CSV в DataFrame можно воспользоваться функцией read_csv библиотеки pandas. Следующий фрагмент загружает и выводит CSV-файл accounts.csv, который был создан ранее в этой главе:
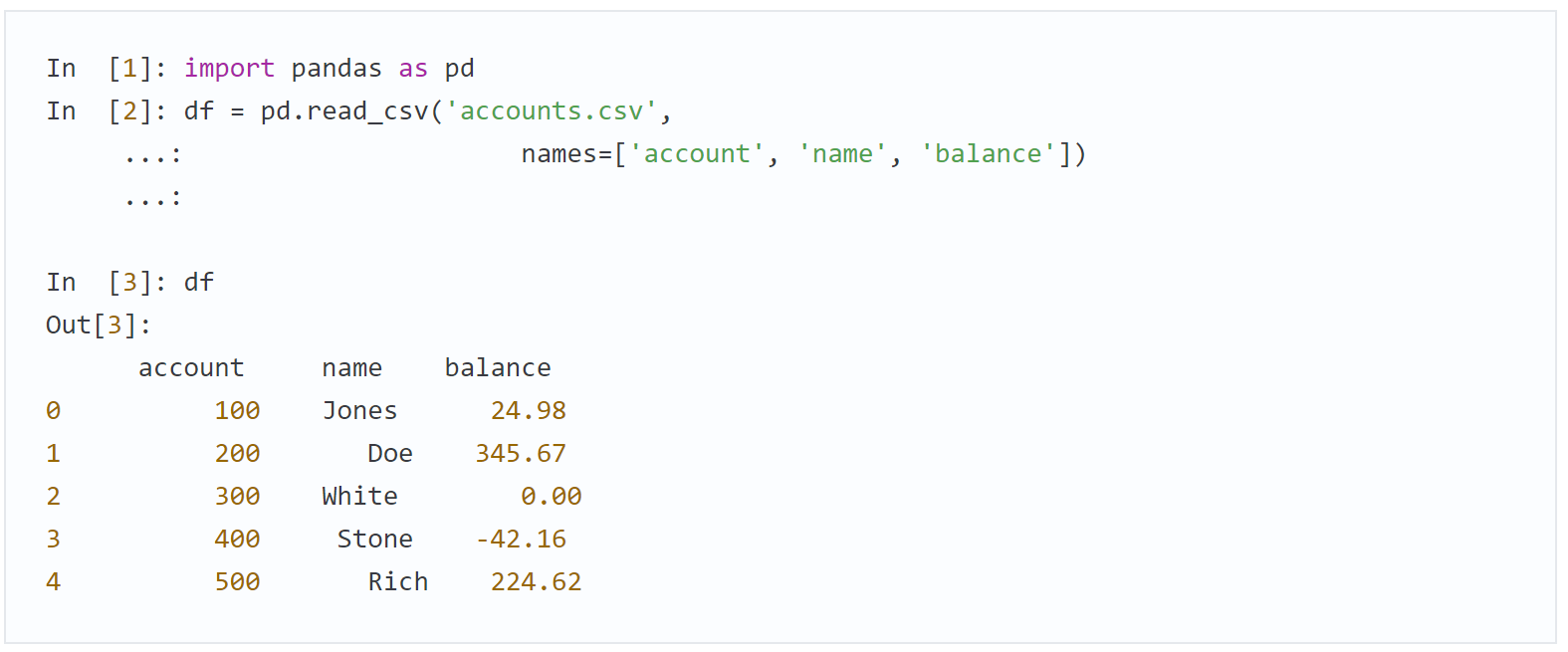
Аргумент names задает имена столбцов DataFrame. Без этого аргумента read_csv считает, что первая строка CSV-файла содержит разделенный запятыми список имен столбцов.
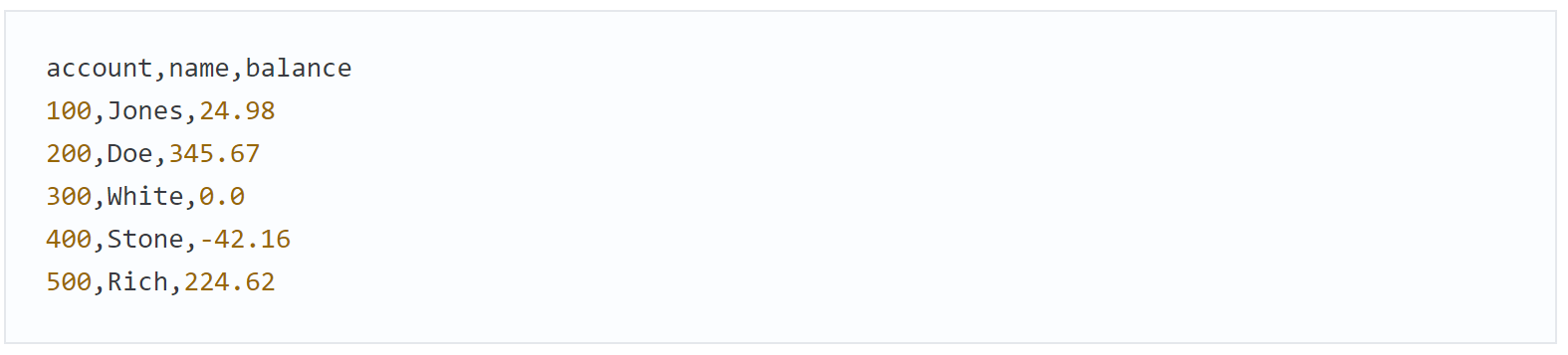
Чтобы сохранить данные DataFrame в файле формата CSV, вызовите метод to_csv коллекции DataFrame:

Ключевой аргумент index=False означает, что имена строк (0–4 в левой части вывода DataFrame в фрагменте [3]) не должны записываться в файл. Первая строка полученного файла содержит имена столбцов:
С полным содержанием статьи можно ознакомиться на сайте "Хабрахабр": https://habr.com/ru/company/piter/blog/500886/
Комментарии: 0
Пока нет комментариев