


Новости

04.05.2022
Книга «Black Hat Python: программирование для хакеров и пентестеров, 2-е изд»
Во втором издании бестселлера Black Hat Python вы исследуете темную сторону возможностей Python — все от написания сетевых снифферов, похищения учетных данных электронной почты и брутфорса каталогов до разработки мутационных фаззеров, анализа виртуальных машин и создания скрытых троянов.
С тех пор как я написал предисловие к первому чрезвычайно успешному изданию Black Hat Python, прошло шесть лет. За это время в мире многое изменилось, но я по-прежнему пишу чертовски много кода на Python. В сфере компьютерной безопасности все еще встречаются инструменты, написанные на разных языках, в зависимости от назначения. Эксплойты для ядра создают на C, средства фаззинга для веб-страниц — на JavaScript, а прокси-серверы могут быть написаны на таком новомодном языке, как Rust. Однако Python остается главной рабочей лошадкой в этой отрасли. Я считаю, что это все еще самый простой язык для начинающих и лучший выбор для быстрой разработки инструментов, решающих сложные задачи простым способом, учитывая большое количество доступных библиотек. Большая часть средств компьютерной безопасности и эксплойтов, как и раньше, написана на Python. Это касается фреймворков создания эксплойтов наподобие CANVAS, классических фаззеров, таких как Sulley, и всего остального.
Веб-хакерство
Навыки анализа веб-приложений совершенно необходимы любому хакеру или пентестеру. В большинстве современных сетей веб-приложения имеют самый высокий потенциал для взлома, поэтому несанкционированный доступ к ним чаще всего получают через них самих.
На Python написано множество отличных веб-инструментов, включая w3af и sqlmap. Если честно, то такие темы, как внедрение SQL-кода, являются крайне заезженными, а готовый инструментарий достаточно развитой для того, чтобы не изобретать велосипед. Поэтому сосредоточимся на основах работы с сетью при помощи Python и затем, опираясь на эти знания, разработаем собственные инструменты для сбора полезных сведений и анализа веб-приложения методом перебора. Это позволит вам приобрести фундаментальные навыки и умения, необходимые для создания любого рода средств анализа веб-приложений, уместных в конкретной атаке.
В этой главе мы рассмотрим три сценария атаки. В первом из них вам известно, какой каркас веб-приложений применяет жертва, и так сложилось, что он имеет открытый исходный код. Каркас веб-приложений содержит множество файлов и вложенных каталогов. Мы сгенерируем локальную карту иерархии веб-приложения и воспользуемся ею для поиска реальных файлов и каталогов на компьютере жертвы.
Во втором сценарии вам известен только URL-адрес жертвы, поэтому придется прибегнуть к методу перебора, чтобы получить ту же структуру каталогов. Мы возьмем словарь и сгенерируем на его основе набор путей и названий каталогов, которые могут присутствовать на атакуемом компьютере. Затем попытаемся отобрать из полученного списка потенциальных путей те, которые действительно существуют.
В третьем сценарии вам известны базовый URL-адрес жертвы и страница для входа. Мы проанализируем эту страницу и попробуем подобрать учетные данные по словарю.
Использование веб-библиотек
Для начала сделаем краткий обзор библиотек, которые можно применять для взаимодействия с веб-сервисами. При выполнении сетевых атак вы можете пользоваться либо своим компьютером, либо устройством внутри атакуемой сети. Если вы пробрались на взломанный компьютер, то придется работать с тем, что под рукой, — это может быть базовая версия Python 2.х или Python 3.х. Мы поговорим о том, что можно сделать в такой ситуации, обходясь стандартной библиотекой. Однако в остальных разделах этой главы предполагается, что на компьютере, с которого проводится атака, установлены самые свежие пакеты.
Библиотека urllib2 для Python 2.х
В коде, написанном на Python 2.х, можно встретить пакет urllib2, встроенный в стандартную библиотеку. Если пакет socket применяется для написания сетевого инструментария, то с помощью urllib2 создают средства взаимодействия с веб-сервисами. Рассмотрим код, который выполняет очень простой GET-запрос к веб-сайту No Starch Press:

Это простейший пример того, как выполнить GET-запрос к веб-сайту. Мы передаем URL-адрес функции urlopen, которая возвращает объект, похожий на дескриптор, с его помощью можем прочитать тело того, что нам возвращает веб-сервер. Поскольку мы получаем всего лишь код страницы с веб-сайта No Starch, никакие клиентские скрипты, написанные на JavaScript или другом языке, выполняться не будут.
Однако в большинстве случаев требуется более гибкий подход к выполнению запросов. Например, иногда нужно указывать определенные заголовки, обрабатывать cookie и создавать запросы типа POST. Библиотека urllib2 имеет в своем составе класс Request, способный обеспечить такой уровень гибкости. В следующем примере показано, как с помощью этого класса создать такой же GET-запрос с указанием собственного HTTP-заголовка User-Agent:

Процесс создания объекта Request немного отличается от того, который мы видели в предыдущем примере. Чтобы указать собственные заголовки, добавляем их названия и значения в словарь headers. В данном случае мы сделаем так, чтобы наш скрипт представлялся поисковым роботом Googlebot. Затем создаем объект Request, предоставляя ему url и словарь headers, после чего передаем этот объект функции urlopen. В ответ получаем обычный объект-дескриптор, который можно использовать для чтения данных с удаленного веб-сайта.
Библиотека urllib для Python 3.х
Стандартная библиотека Python 3.х содержит пакет urllib, в котором возможности urllib2 разделены на два подпакета: urllib.request и urllib.error. Также в urllib появились функции разбора URL-адресов, доступные в подпакете urllib.parse.
Для создания HTTP-запроса с помощью urllib можно воспользоваться диспетчером контекста и инструкцией with. Полученный ответ должен содержать байтовую строку. Вот как это выглядит на примере GET-запроса:

Здесь мы импортируем нужные нам пакеты и определяем целевой URL-адрес. Затем с помощью метода urlopen в качестве диспетчера контекста выполняем запрос и читаем ответ.
Чтобы создать POST-запрос, передайте словарь с данными, закодированными в виде байтов, объекту Request. Этот словарь должен содержать пары «ключ — значение», которые ожидает получить атакуемое вами веб-приложение. В этом примере словарь info содержит учетные данные (user, passwd), необходимые для входа на веб-сайт:
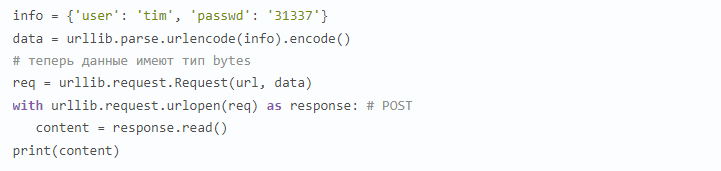
Мы кодируем словарь с учетными данными, чтобы превратить его в объект типа bytes, помещаем его в POST-запрос, передающий эти учетные данные, и принимаем ответ на попытку входа в веб-приложение.
Библиотека requests
Даже официальная документация Python рекомендует использовать в качестве высокоуровневого клиентского HTTP-интерфейса пакет requests. Он не входит в стандартную библиотеку, поэтому его нужно устанавливать отдельно. Вот как это сделать с помощью pip:
![]()
Пакет requests выгодно отличается тем, что может автоматически обрабатывать cookie, и в этом вы сами сможете убедиться в следующем примере, хотя наиболее наглядно это будет представлено в ходе демонстрационной атаки на веб-сайт WordPress, которую мы проведем в разделе «Взлом HTML-формы аутентификации методом перебора» далее. Для выполнения HTTP-запроса проделайте следующее:
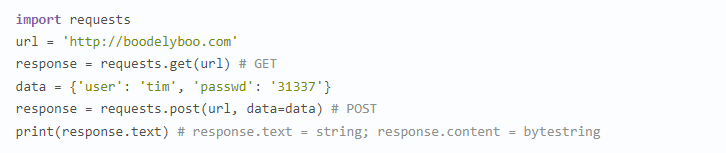
Создаем url, request и словарь data с ключами user и passwd. Затем отправляем запрос методом POST и выводим атрибут text (строку). Если вы предпочитаете работать с байтовыми строками, используйте атрибут content, возвращенный вместе с ответом. Пример этого будет показан в разделе «Взлом HTML-формы аутентификации методом перебора».
Приобрести книгу можно на сайте издательства:
Комментарии: 0
Пока нет комментариев